Build a Programmatic SEO Engine on Next.js: Architecture, Pipeline, and the Pitfalls That Tank It
You decided programmatic SEO is worth doing. Now you have to build it. Here is the Next.js architecture, the data pipeline, the rendering choices, and the technical mistakes that quietly kill these projects.
11 min read
Our last post on programmatic SEO was the strategy layer: when it still works in 2026 and when Google penalizes it. It ended with a six-test framework for deciding whether a project is worth building at all.
This post assumes you ran that framework, the project passed, and now you have to actually build the thing. It is the technical companion: the Next.js architecture, the data pipeline, the rendering decisions, the internal linking implementation, and the engineering mistakes that quietly tank programmatic SEO projects even when the strategy was sound.
It is written for the developer or technical founder who has the dataset and the templates and now needs an architecture that ranks, scales past a few thousand pages, and does not collapse under its own maintenance burden.
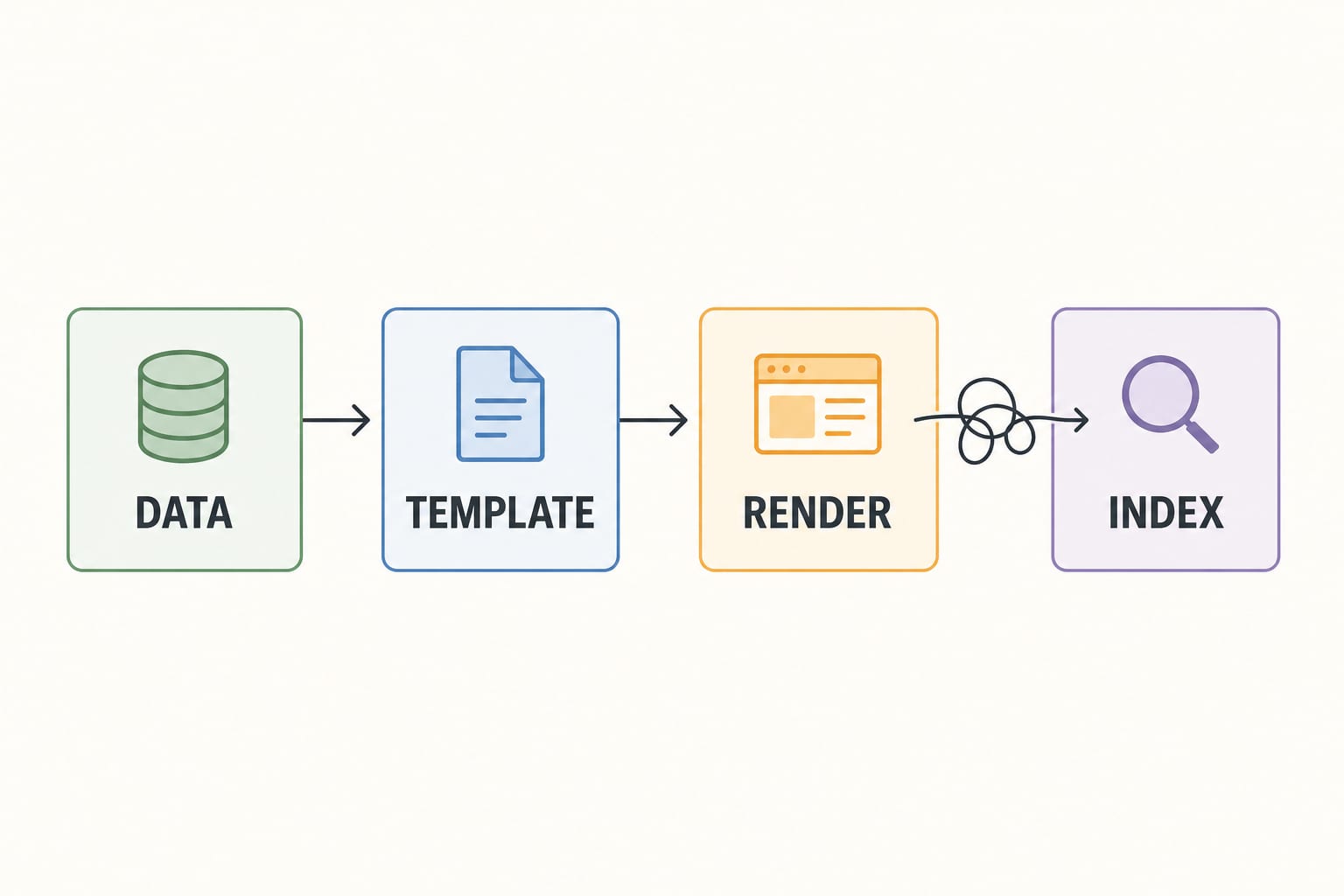
The architecture in one diagram
A programmatic SEO engine on Next.js has four layers. Get the boundaries right and the system stays maintainable. Blur them and you get a tangle that nobody wants to touch in twelve months.
The rest of this post walks each layer.
Layer 1: the data layer
The most important architectural decision is upstream of any code. The data has to be owned, structured, and maintainable. We made this point in the strategy post and it bears repeating because it is where projects fail before the first commit: scraped data dies, owned data compounds.
For most projects, Postgres is the right home. It gives you real querying, relationships, constraints, and a clean migration story. Airtable works for smaller projects where non-technical team members maintain the data, with the tradeoff of API rate limits and weaker querying. Google Sheets is viable for the smallest projects, sub-thousand pages, where the data is genuinely simple. If the engine lives inside a Shopify store, Shopify Metaobjects are a legitimate data layer and avoid running a separate database.
Whatever the store, the schema should be explicit. A page is a row, or a deterministic combination of rows. Every field that appears on a page maps to a column. The generation layer should never invent data; it only renders what the data layer holds.
-- Postgres: a location-page programmatic SEO engine
CREATE TABLE pages (
id bigint PRIMARY KEY,
slug text UNIQUE NOT NULL,
primary_kw text NOT NULL,
city text NOT NULL,
region text NOT NULL,
-- structured attributes that differentiate the page
avg_price numeric,
provider_count integer,
open_late_pct numeric,
-- page-specific generated summary, reviewed by a human
summary text,
-- freshness tracking
data_updated timestamptz NOT NULL,
status text NOT NULL DEFAULT 'draft' -- draft | live | retired
);The status column matters more than it looks. It lets the generation layer publish only live pages, hold draft pages back until they have real content, and retire underperformers without deleting the row. Programmatic SEO sites that cannot retire their own dead pages accumulate weight that drags the whole domain.
Layer 2: the generation layer
This is where Next.js App Router does the work. Two functions carry most of the load.
generateStaticParams tells Next.js which pages exist. It queries the data layer for every live page and returns the route params.
// app/guides/[slug]/page.tsx
export async function generateStaticParams() {
const pages = await db.query(
"SELECT slug FROM pages WHERE status = 'live'"
);
return pages.map((p) => ({ slug: p.slug }));
}generateMetadata produces the per-page title, description, and Open Graph data. This must be page-specific. Generic, templated metadata is one of the clearest low-quality signals, and it is the easiest thing to get right.
export async function generateMetadata({ params }) {
const page = await getPage(params.slug);
if (!page) return {};
return {
title: `${page.primary_kw} in ${page.city}: ${page.provider_count} options compared`,
description: `Compare ${page.provider_count} ${page.primary_kw} options in ${page.city}. Average price ${page.avg_price}. Updated ${formatDate(page.data_updated)}.`,
alternates: { canonical: `https://example.com/guides/${page.slug}` },
openGraph: {
title: `${page.primary_kw} in ${page.city}`,
type: "article"
}
};
}Notice the metadata pulls real numbers from the data layer: provider count, average price, update date. That specificity is what separates a useful page from a templated husk. It is also what makes the page legible to AI agents, which lean on structured specifics to decide whether to cite a source.
The route component itself fetches the page record and renders it. Keep the fetch in a server component so the HTML is fully formed before it reaches the browser.
Layer 3: the render layer
Three technical decisions in this layer decide whether the project ranks.
Render static, not client-side
Programmatic SEO pages should be static HTML or server-rendered, never client-side rendered. The reasons compound: client-rendered pages are slower, they are more expensive for search engines to crawl, JavaScript SEO introduces a rendering step that can fail or lag, and AI agents that read your pages strongly prefer content present in the initial HTML response.
In App Router terms: server components by default, generateStaticParams for the page set, and ISR (incremental static regeneration) for the refresh story. The page should be fully formed HTML when it leaves the server. If you find yourself reaching for useEffect to fetch the page's core content, the architecture has gone wrong.
This is the same principle behind our Hydrogen versus Next.js comparison: the rendering model is not a detail, it is the thing that decides whether the content is visible to crawlers and agents at all.
Make each page genuinely page-specific
The template provides structure. The data provides differentiation. But template plus raw data is rarely enough on its own. The pages that rank in 2026 also carry:
A page-specific summary or analysis. This can be generated, but it must reflect the specific data of that page, and it should be reviewed. A summary that says "City X has 14 providers with an average price of Y, notably higher than the regional average" is specific and true. A summary that says "City X is a great place to find providers" is boilerplate and gets filtered.
Examples or scenarios tied to the page's particular combination of variables.
A meaningful action the user can take from the page.
The rough bar: 30 to 50 percent of the words on each page should be specific to that page rather than shared with every sibling. Below that, the template-to-content ratio reads as scaled content.
Emit structured data per page
Every programmatic page should carry JSON-LD appropriate to its type, ItemList for directory pages, Article for guide pages, Product for product pages, FAQPage where you have a real FAQ. We covered the AI-aware property set in depth in our schema markup post; the same discipline applies here. The schema is generated from the same data layer that produces the visible content, so it stays consistent automatically.
// inside the route component, server-side
function buildSchema(page) {
return {
"@context": "https://schema.org",
"@type": "Article",
headline: `${page.primary_kw} in ${page.city}`,
dateModified: page.data_updated,
about: {
"@type": "Thing",
name: page.primary_kw
},
// structured specifics that AI agents read
mainEntity: {
"@type": "ItemList",
numberOfItems: page.provider_count
}
};
}Layer 4: the refresh layer
This is the layer most teams skip and the reason most programmatic SEO projects decay. A project without a refresh pipeline is not a project; it is a one-time publish that rots.
The refresh cadence depends on what the data is. Pricing data refreshes daily. Geographic and provider data refreshes monthly. Category-level statistics refresh quarterly. The architecture should refresh only what changed, not rebuild the entire site on every cycle.
Next.js on-demand ISR makes this clean. When a record changes in the data layer, a webhook or cron job hits a revalidation endpoint for exactly the affected page paths.
// app/api/revalidate/route.ts
import { revalidatePath } from "next/cache";
export async function POST(request) {
const { secret, slugs } = await request.json();
if (secret !== process.env.REVALIDATE_SECRET) {
return new Response("Unauthorized", { status: 401 });
}
for (const slug of slugs) {
revalidatePath(`/guides/${slug}`);
}
return Response.json({ revalidated: true, count: slugs.length });
}The other half of this layer is observability. You need per-page traffic, conversion, and AI-citation tracking, because programmatic SEO sites have to prune their own underperformers. Pages that consistently bring nothing get reviewed, improved, or moved to status = 'retired'. Without this feedback loop, the site only ever accumulates, and accumulation is what eventually triggers a quality demotion.
The internal linking implementation
Internal linking on programmatic SEO sites is the single clearest tell of low-quality intent, and it is also straightforward to do well.
The rule from the strategy post: the links from a page should be the links a real user on that page would actually want. Implement that as a similarity function, not a footer dump.
// compute related pages by shared attributes, not by stuffing every link
function relatedPages(page, allPages, limit = 10) {
return allPages
.filter((p) => p.slug !== page.slug && p.status === "live")
.map((p) => ({
page: p,
score:
(p.region === page.region ? 3 : 0) +
(p.primary_kw === page.primary_kw ? 2 : 0) +
(Math.abs(p.avg_price - page.avg_price) < 20 ? 1 : 0)
}))
.filter((x) => x.score > 0)
.sort((a, b) => b.score - a.score)
.slice(0, limit)
.map((x) => x.page);
}Cap outbound internal links at roughly 8 to 12 genuinely related pages. No exhaustive "see also" blocks, no footer link farms. A constrained, relevant link graph reads as a useful site. An unconstrained one reads as a link scheme, and Google has been efficient at telling the two apart since 2024.
The pitfalls that tank the project
Even with a sound strategy, the engineering can sink it. The mistakes we see most:
Client-side rendering the core content. The page's main content arrives via useEffect instead of being in the server HTML. Crawlers and AI agents see a near-empty shell. This is the single most common technical failure.
Unstable URLs. The slug changes on every regeneration because it is derived from a field that gets re-normalized. Every regeneration discards the page's accumulated link equity. Slugs must be stable and stored, not recomputed.
No status discipline. Every row becomes a live page the moment it exists, including the thin ones with no real content. The thin pages drag down the good ones. Use the status column; publish live only.
Templated metadata. generateMetadata returns the same shape with the city name swapped in. Page-specific numbers and specifics are right there in the data layer; use them.
No refresh layer. The site is built once and never updated. Within a year the prices are wrong, the counts are stale, and AI agents that cross-reference catch it faster than Google does.
Building 50,000 pages when the data supports 800. The strategy post said it and it is an engineering decision too: generate pages the data justifies. Padding the page count with thin combinations is worse than shipping fewer strong pages.
No observability. The team cannot see which pages perform, so they cannot prune. The site only accumulates, and accumulation is what eventually triggers a quality problem.
⚙
A programmatic SEO engine is a content system, not a one-time script. Budget for the refresh layer and the observability layer the same way you budget for the generation layer. The projects that compound for years are the ones that were architected to be maintained, not just launched.
FAQ
App Router or Pages Router for this?
App Router. generateStaticParams, generateMetadata, server components by default, and on-demand revalidatePath give you a cleaner static-generation and refresh story than the Pages Router equivalent. If you are on an existing Pages Router codebase, the patterns translate, but new projects should start on App Router.
Static export, ISR, or SSR?
For most programmatic SEO engines, ISR is the right balance: pages are static and fast, and the refresh layer can revalidate individual pages on demand when the data changes. Full static export works if the data refreshes rarely. SSR is rarely right here; it adds per-request cost without a ranking benefit, since the content is the same for every visitor.
Can I generate the page-specific summaries with AI?
Yes, with the caveat from the strategy post: AI-generated text is fine when it summarizes or explains the page's real structured data, and it should be reviewed. It is not fine as the page's only content or when it is generic. The bar is whether the text reflects something specific and true about that page.
How do I handle pagination on directory-style pages?
Keep paginated URLs stable and crawlable, use rel next/prev sparingly, and make sure each paginated page still carries enough page-specific value to justify existing. If page 7 of a list is just more rows with no added context, consider whether it should be indexable at all.
What about international and multilingual programmatic SEO?
It multiplies the page count and the complexity. Each language and country variant must be a real translation against a verified local dataset, with correct hreflang. Auto-translated programmatic pages against unvalidated data are exactly the pattern Google demoted in 2024. We covered the hreflang mechanics in hreflang on Shopify; the principles carry over to a Next.js engine.
How many pages before I need a real database instead of a Sheet?
Roughly a thousand pages, or whenever non-technical maintenance and querying start to hurt. Below that, Sheets or Airtable are fine. Above it, the lack of real constraints, relationships, and migration tooling starts to cost more than the database would.
Where to go from here
If you have the dataset and the strategy validated and you want help building the engine, get in touch. We typically scope the data layer and the generation architecture in a short technical workshop, then build the Next.js engine, the refresh pipeline, and the observability layer together. You can also read about our broader SaaS and web app development work and our technical SEO engineering service, which is where programmatic SEO sits in our stack.
For the strategy side, start with programmatic SEO in 2026: when it works. For the structured-data layer that makes these pages legible to AI agents, see schema markup for Shopify in 2026.
Related posts
View all articles
Technical SEOApr 30, 2026
Programmatic SEO in 2026: When It Still Works, When Google Penalizes It, and How to Tell the Difference
Programmatic SEO is not dead. It is just no longer easy. Here is the framework we use in 2026 to decide whether a programmatic SEO project will compound traffic or get nuked by the Helpful Content system in six months.
14 min read

Custom SoftwareJun 24, 2026
Custom CRM vs Off-the-Shelf in 2026: When Building Your Own Actually Wins
Most teams should buy a CRM. Some should not. Here is the decision framework we use with clients, the cost math at scale, and the specific operational shapes where a custom build outperforms HubSpot, Salesforce, and the lower-cost alternatives.
13 min read
Custom SoftwareMay 26, 2026
Choosing Authentication for a New SaaS in 2026: Clerk, Auth.js, Supabase Auth, Better Auth, and When to Self-Host
Authentication is the least exciting part of a SaaS build until it breaks or the bill arrives. Here is how we choose between Clerk, Auth.js, Supabase Auth, Better Auth, and a custom build for client projects in 2026.
12 min read