Construire un moteur de programmatic SEO sur Next.js : architecture, pipeline et les pièges qui le coulent
Vous avez décidé que le programmatic SEO valait le coup. Maintenant il faut le construire. Voici l'architecture Next.js, le pipeline de données, les choix de rendu et les erreurs techniques qui tuent silencieusement ces projets.
13 min de lecture
Notre dernier post sur le programmatic SEO était la couche stratégie : quand ça marche encore en 2026 et quand Google pénalise. Il se terminait sur un cadre à six tests pour décider si un projet vaut le coup d'être construit.
Ce post suppose que vous avez déroulé ce cadre, que le projet est passé, et que maintenant il faut réellement construire la chose. C'est le compagnon technique : l'architecture Next.js, le pipeline de données, les décisions de rendu, l'implémentation du maillage interne, et les erreurs d'ingénierie qui coulent silencieusement les projets de programmatic SEO même quand la stratégie était saine.
Il est écrit pour le développeur ou le fondateur technique qui a le dataset et les templates et qui a maintenant besoin d'une architecture qui se classe, passe à l'échelle au-delà de quelques milliers de pages, et ne s'effondre pas sous son propre fardeau de maintenance.
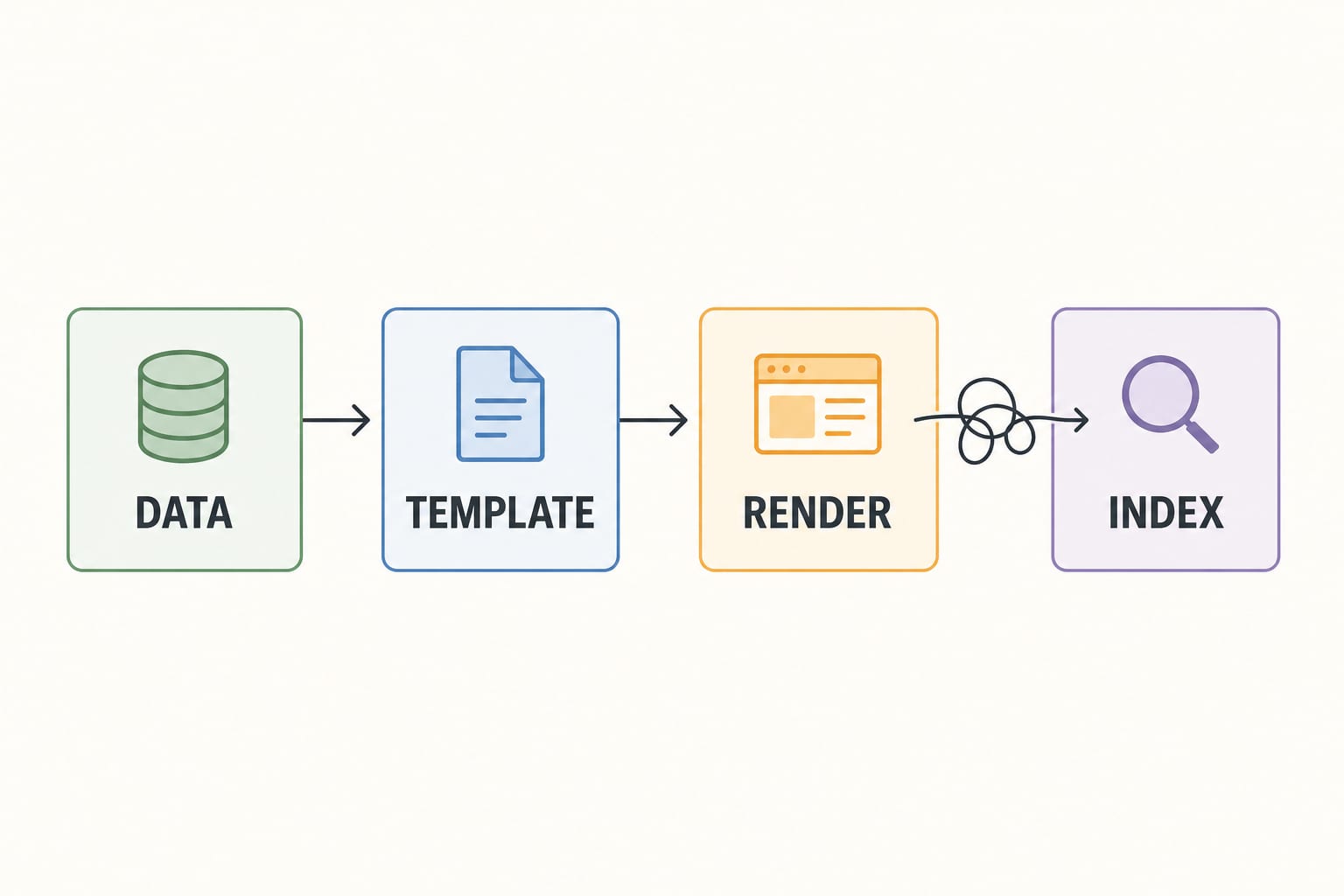
L'architecture en un schéma
Un moteur de programmatic SEO sur Next.js a quatre couches. Posez bien les frontières et le système reste maintenable. Brouillez-les et vous obtenez un enchevêtrement que personne ne veut toucher dans douze mois.
Le reste de ce post parcourt chaque couche.
Couche 1 : la couche de données
La décision d'architecture la plus importante est en amont de tout code. Les données doivent être possédées, structurées et maintenables. Nous avons fait ce point dans le post stratégie et il mérite d'être répété parce que c'est là que les projets échouent avant le premier commit : les données scrapées meurent, les données possédées capitalisent.
Pour la plupart des projets, Postgres est le bon foyer. Il vous donne du vrai requêtage, des relations, des contraintes et une histoire de migration propre. Airtable fonctionne pour les plus petits projets où des membres non techniques maintiennent les données, avec l'arbitrage des rate limits API et d'un requêtage plus faible. Google Sheets est viable pour les plus petits projets, sous le millier de pages, où les données sont vraiment simples. Si le moteur vit dans une boutique Shopify, les Shopify Metaobjects sont une couche de données légitime et évitent de faire tourner une base séparée.
Quel que soit le foyer, le schéma doit être explicite. Une page est une ligne, ou une combinaison déterministe de lignes. Chaque champ qui apparaît sur une page se mappe sur une colonne. La couche de génération ne doit jamais inventer de données ; elle ne fait que rendre ce que la couche de données contient.
-- Postgres : un moteur de programmatic SEO de pages de localisation
CREATE TABLE pages (
id bigint PRIMARY KEY,
slug text UNIQUE NOT NULL,
primary_kw text NOT NULL,
city text NOT NULL,
region text NOT NULL,
-- attributs structurés qui différencient la page
avg_price numeric,
provider_count integer,
open_late_pct numeric,
-- résumé généré spécifique à la page, relu par un humain
summary text,
-- suivi de fraîcheur
data_updated timestamptz NOT NULL,
status text NOT NULL DEFAULT 'draft' -- draft | live | retired
);La colonne status compte plus qu'il n'y paraît. Elle permet à la couche de génération de publier seulement les pages live, de retenir les pages draft jusqu'à ce qu'elles aient un vrai contenu, et de retirer (retire) les sous-performances sans supprimer la ligne. Les sites de programmatic SEO qui ne peuvent pas retirer leurs propres pages mortes accumulent du poids qui tire tout le domaine vers le bas.
Couche 2 : la couche de génération
C'est là que Next.js App Router fait le travail. Deux fonctions portent l'essentiel de la charge.
generateStaticParams dit à Next.js quelles pages existent. Elle interroge la couche de données pour chaque page live et retourne les params de route.
// app/guides/[slug]/page.tsx
export async function generateStaticParams() {
const pages = await db.query(
"SELECT slug FROM pages WHERE status = 'live'"
);
return pages.map((p) => ({ slug: p.slug }));
}generateMetadata produit le title, la description et les données Open Graph par page. Cela doit être spécifique à la page. Les métadonnées génériques et templatisées sont l'un des signaux de basse qualité les plus clairs, et c'est la chose la plus facile à bien faire.
export async function generateMetadata({ params }) {
const page = await getPage(params.slug);
if (!page) return {};
return {
title: `${page.primary_kw} à ${page.city} : ${page.provider_count} options comparées`,
description: `Comparez ${page.provider_count} options ${page.primary_kw} à ${page.city}. Prix moyen ${page.avg_price}. Mis à jour le ${formatDate(page.data_updated)}.`,
alternates: { canonical: `https://example.com/guides/${page.slug}` },
openGraph: {
title: `${page.primary_kw} à ${page.city}`,
type: "article"
}
};
}Remarquez que les métadonnées tirent de vrais chiffres de la couche de données : nombre de prestataires, prix moyen, date de mise à jour. Cette spécificité est ce qui sépare une page utile d'une coquille templatisée. C'est aussi ce qui rend la page lisible pour les agents IA, qui s'appuient sur des spécificités structurées pour décider de citer une source.
Le composant de route lui-même récupère l'enregistrement de la page et la rend. Gardez le fetch dans un server component pour que le HTML soit entièrement formé avant d'atteindre le navigateur.
Couche 3 : la couche de rendu
Trois décisions techniques dans cette couche déterminent si le projet se classe.
Rendre en statique, pas côté client
Les pages de programmatic SEO doivent être du HTML statique ou rendu côté serveur, jamais rendu côté client. Les raisons se cumulent : les pages rendues côté client sont plus lentes, elles sont plus chères à crawler pour les moteurs de recherche, le JavaScript SEO introduit une étape de rendu qui peut échouer ou prendre du retard, et les agents IA qui lisent vos pages préfèrent fortement le contenu présent dans la réponse HTML initiale.
En termes App Router : server components par défaut, generateStaticParams pour l'ensemble de pages, et ISR (incremental static regeneration) pour l'histoire du refresh. La page doit être du HTML entièrement formé quand elle quitte le serveur. Si vous vous surprenez à attraper useEffect pour récupérer le contenu principal de la page, l'architecture a mal tourné.
C'est le même principe derrière notre comparatif Hydrogen versus Next.js : le modèle de rendu n'est pas un détail, c'est la chose qui décide si le contenu est visible pour les crawlers et les agents tout court.
Rendre chaque page vraiment spécifique
Le template fournit la structure. Les données fournissent la différenciation. Mais le template plus les données brutes suffisent rarement seuls. Les pages qui se classent en 2026 portent aussi :
Un résumé ou une analyse spécifique à la page. Cela peut être généré, mais cela doit refléter les données spécifiques de cette page, et cela doit être relu. Un résumé qui dit "La ville X a 14 prestataires avec un prix moyen de Y, nettement au-dessus de la moyenne régionale" est spécifique et vrai. Un résumé qui dit "La ville X est un super endroit pour trouver des prestataires" est du boilerplate et se fait filtrer.
Des exemples ou scénarios liés à la combinaison particulière de variables de la page.
Une action significative que l'utilisateur peut faire depuis la page.
La barre approximative : 30 à 50 pour cent des mots de chaque page doivent être spécifiques à cette page plutôt que partagés avec chaque page sœur. En dessous, le ratio template/contenu se lit comme du scaled content.
Émettre des données structurées par page
Chaque page programmatic doit porter du JSON-LD approprié à son type, ItemList pour les pages d'annuaire, Article pour les pages de guide, Product pour les pages produit, FAQPage là où vous avez une vraie FAQ. Nous avons couvert le jeu de propriétés AI-aware en profondeur dans notre post schema markup ; la même discipline s'applique ici. Le schema est généré depuis la même couche de données qui produit le contenu visible, donc il reste cohérent automatiquement.
// dans le composant de route, côté serveur
function buildSchema(page) {
return {
"@context": "https://schema.org",
"@type": "Article",
headline: `${page.primary_kw} à ${page.city}`,
dateModified: page.data_updated,
about: {
"@type": "Thing",
name: page.primary_kw
},
// spécificités structurées que les agents IA lisent
mainEntity: {
"@type": "ItemList",
numberOfItems: page.provider_count
}
};
}Couche 4 : la couche de refresh
C'est la couche que la plupart des équipes sautent et la raison pour laquelle la plupart des projets de programmatic SEO se dégradent. Un projet sans pipeline de refresh n'est pas un projet ; c'est une publication unique qui pourrit.
La cadence de refresh dépend de ce que sont les données. Les données prix se rafraîchissent quotidiennement. Les données géographiques et de prestataires se rafraîchissent mensuellement. Les statistiques au niveau catégorie se rafraîchissent trimestriellement. L'architecture doit rafraîchir seulement ce qui a changé, pas reconstruire tout le site à chaque cycle.
L'ISR à la demande de Next.js rend cela propre. Quand un enregistrement change dans la couche de données, un webhook ou un cron job frappe un endpoint de revalidation pour exactement les chemins de pages affectés.
// app/api/revalidate/route.ts
import { revalidatePath } from "next/cache";
export async function POST(request) {
const { secret, slugs } = await request.json();
if (secret !== process.env.REVALIDATE_SECRET) {
return new Response("Unauthorized", { status: 401 });
}
for (const slug of slugs) {
revalidatePath(`/guides/${slug}`);
}
return Response.json({ revalidated: true, count: slugs.length });
}L'autre moitié de cette couche est l'observabilité. Il vous faut le trafic par page, la conversion et le suivi des citations IA, parce que les sites de programmatic SEO doivent tailler leurs propres sous-performances. Les pages qui n'apportent constamment rien sont revues, améliorées ou passées en status = 'retired'. Sans cette boucle de feedback, le site ne fait qu'accumuler, et l'accumulation est ce qui finit par déclencher un déclassement qualité.
L'implémentation du maillage interne
Le maillage interne sur les sites de programmatic SEO est le signal le plus clair d'une intention de basse qualité, et c'est aussi simple à bien faire.
La règle du post stratégie : les liens depuis une page doivent être les liens qu'un utilisateur réel sur cette page voudrait réellement suivre. Implémentez cela comme une fonction de similarité, pas un dump de footer.
// calculer les pages liées par attributs partagés, pas en empilant chaque lien
function relatedPages(page, allPages, limit = 10) {
return allPages
.filter((p) => p.slug !== page.slug && p.status === "live")
.map((p) => ({
page: p,
score:
(p.region === page.region ? 3 : 0) +
(p.primary_kw === page.primary_kw ? 2 : 0) +
(Math.abs(p.avg_price - page.avg_price) < 20 ? 1 : 0)
}))
.filter((x) => x.score > 0)
.sort((a, b) => b.score - a.score)
.slice(0, limit)
.map((x) => x.page);
}Plafonnez les liens internes sortants à environ 8 à 12 pages réellement liées. Pas de blocs "voir aussi" exhaustifs, pas de fermes de liens en footer. Un graph de liens contraint et pertinent se lit comme un site utile. Un graph non contraint se lit comme un schéma de liens, et Google a été efficace à distinguer les deux depuis 2024.
Les pièges qui coulent le projet
Même avec une stratégie saine, l'ingénierie peut le couler. Les erreurs que nous voyons le plus :
Rendre le contenu principal côté client. Le contenu principal de la page arrive via useEffect au lieu d'être dans le HTML serveur. Les crawlers et les agents IA voient une coquille quasi vide. C'est l'échec technique le plus courant.
URLs instables. Le slug change à chaque régénération parce qu'il est dérivé d'un champ qui est re-normalisé. Chaque régénération jette l'autorité de liens accumulée de la page. Les slugs doivent être stables et stockés, pas recalculés.
Pas de discipline status. Chaque ligne devient une page live dès qu'elle existe, y compris les maigres sans vrai contenu. Les pages maigres tirent les bonnes vers le bas. Utilisez la colonne status ; ne publiez que live.
Métadonnées templatisées. generateMetadata retourne la même forme avec le nom de ville changé. Les chiffres et spécificités par page sont juste là dans la couche de données ; utilisez-les.
Pas de couche de refresh. Le site est construit une fois et jamais mis à jour. En un an les prix sont faux, les comptages périmés, et les agents IA qui recoupent l'attrapent plus vite que Google.
Construire 50 000 pages quand les données en supportent 800. Le post stratégie l'a dit et c'est aussi une décision d'ingénierie : générez les pages que les données justifient. Rembourrer le compteur de pages avec des combinaisons maigres est pire que de livrer moins de pages fortes.
Pas d'observabilité. L'équipe ne peut pas voir quelles pages performent, donc elle ne peut pas tailler. Le site ne fait qu'accumuler, et l'accumulation est ce qui finit par déclencher un problème de qualité.
⚙
Un moteur de programmatic SEO est un système de contenu, pas un script unique. Budgétez la couche de refresh et la couche d'observabilité de la même manière que vous budgétez la couche de génération. Les projets qui capitalisent pendant des années sont ceux qui ont été architecturés pour être maintenus, pas seulement lancés.
FAQ
App Router ou Pages Router pour ça ?
App Router. generateStaticParams, generateMetadata, les server components par défaut et revalidatePath à la demande vous donnent une histoire de génération statique et de refresh plus propre que l'équivalent Pages Router. Si vous êtes sur une base de code Pages Router existante, les patterns se transfèrent, mais les nouveaux projets devraient démarrer sur App Router.
Export statique, ISR ou SSR ?
Pour la plupart des moteurs de programmatic SEO, l'ISR est le bon équilibre : les pages sont statiques et rapides, et la couche de refresh peut revalider des pages individuelles à la demande quand les données changent. L'export statique complet fonctionne si les données se rafraîchissent rarement. Le SSR est rarement le bon choix ici ; il ajoute du coût par requête sans bénéfice de classement, puisque le contenu est le même pour chaque visiteur.
Puis-je générer les résumés spécifiques aux pages avec de l'IA ?
Oui, avec la réserve du post stratégie : le texte généré par IA est OK quand il résume ou explique les vraies données structurées de la page, et il doit être relu. Il n'est pas OK comme seul contenu de la page ou quand il est générique. La barre est de savoir si le texte reflète quelque chose de spécifique et vrai sur cette page.
Comment gérer la pagination sur les pages de type annuaire ?
Gardez les URLs paginées stables et crawlables, utilisez rel next/prev avec parcimonie, et assurez-vous que chaque page paginée porte encore assez de valeur spécifique pour justifier d'exister. Si la page 7 d'une liste n'est que plus de lignes sans contexte ajouté, demandez-vous si elle devrait être indexable tout court.
Et le programmatic SEO international et multilingue ?
Cela multiplie le nombre de pages et la complexité. Chaque variante de langue et de pays doit être une vraie traduction contre un dataset local vérifié, avec un hreflang correct. Les pages programmatic auto-traduites contre des données non validées sont exactement le pattern que Google a déclassé en 2024. Nous avons couvert la mécanique hreflang dans hreflang sur Shopify ; les principes se transfèrent à un moteur Next.js.
Combien de pages avant d'avoir besoin d'une vraie base de données plutôt qu'un Sheet ?
Environ un millier de pages, ou dès que la maintenance non technique et le requêtage commencent à faire mal. En dessous, Sheets ou Airtable conviennent. Au-dessus, l'absence de vraies contraintes, relations et outillage de migration commence à coûter plus que ne coûterait la base.
Pour aller plus loin
Si vous avez le dataset et la stratégie validée et que vous voulez de l'aide pour construire le moteur, contactez-nous. Nous cadrons typiquement la couche de données et l'architecture de génération dans un court atelier technique, puis construisons le moteur Next.js, le pipeline de refresh et la couche d'observabilité ensemble. Vous pouvez aussi en savoir plus sur notre travail de développement SaaS et applications web et notre service d'ingénierie SEO technique, qui est là où le programmatic SEO se place dans notre stack.
Pour le côté stratégie, commencez par programmatic SEO en 2026 : quand ça marche. Pour la couche de données structurées qui rend ces pages lisibles aux agents IA, voir schema markup pour Shopify en 2026.
Articles connexes
Tous les articles
Technical SEOApr 30, 2026
Programmatic SEO en 2026 : quand ça marche encore, quand Google pénalise, et comment faire la différence
Le programmatic SEO n'est pas mort. Il n'est juste plus facile. Voici le cadre que nous utilisons en 2026 pour décider si un projet de programmatic SEO va capitaliser du trafic ou se faire détruire par le Helpful Content system dans six mois.
16 min de lecture

Custom SoftwareJun 24, 2026
CRM sur mesure vs CRM du commerce en 2026 : quand construire le sien gagne réellement
La plupart des équipes devraient acheter un CRM. Certaines ne devraient pas. Voici le cadre de décision que nous utilisons avec les clients, les calculs de coût à l'échelle, et les formes opérationnelles spécifiques où un build sur mesure surpasse HubSpot, Salesforce et les alternatives moins coûteuses.
14 min de lecture
Custom SoftwareMay 26, 2026
Choisir l'authentification pour un nouveau SaaS en 2026 : Clerk, Auth.js, Supabase Auth, Better Auth, et quand auto-héberger
L'authentification est la partie la moins excitante d'un build SaaS jusqu'à ce qu'elle casse ou que la facture arrive. Voici comment nous choisissons entre Clerk, Auth.js, Supabase Auth, Better Auth et un build sur mesure pour les projets clients en 2026.
13 min de lecture