Développement de MVP SaaS en 2026 : les décisions d'ingénierie qui décident si vous livrez ou si vous coulez
Le cadre d'ingénieur pour le développement de MVP SaaS en 2026. Choix de stack, arbitrages d'architecture, décisions build-vs-buy, infrastructure AWS, et les choix d'ingénierie qui distinguent une startup qui livre d'une qui n'y arrive pas.
18 min de lecture
Chaque article "Comment construire un MVP SaaS en 2026" trouvé sur Google se lit comme la même liste : choisissez un framework JavaScript, déployez sur Vercel, utilisez Stripe pour le paiement, livrez en 4 semaines, félicitations. Les startups qui livrent réellement des MVP ne ressemblent pas à ça. Les startups qui livrent et survivent ressemblent à ça encore moins. Les décisions qui décident si vous avez un produit dans 18 mois ou une perte sèche ne sont pas des choix de framework ; ce sont des choix architecturaux, opérationnels et stratégiques que la plupart du contenu "guide MVP" évite activement parce que les réponses sont inconfortables.
Cet article est le cadre que nous déroulons avec les fondateurs et CTO chez Sentinu quand nous cadrons un build de MVP SaaS. C'est la conversation qui doit avoir lieu avant que le fichier Figma ne soit ouvert et que le repo GitHub ne soit créé. Les équipes qui ont cette conversation en amont livrent des MVP qui survivent au premier contact avec des clients payants. Les équipes qui la sautent reconstruisent généralement depuis zéro dans les 18 mois, ce qui est la manière la plus chère d'apprendre qu'un MVP est une décision d'ingénierie, pas juste une décision produit.
Le MVP qui livre face au MVP qui coule
Après deux décennies à regarder des MVP SaaS atterrir sur le marché, le pattern est constant. Ceux qui livrent et grandissent ont cinq points en commun. Ceux qui échouent (dans notre expérience) en ratent généralement au moins trois.
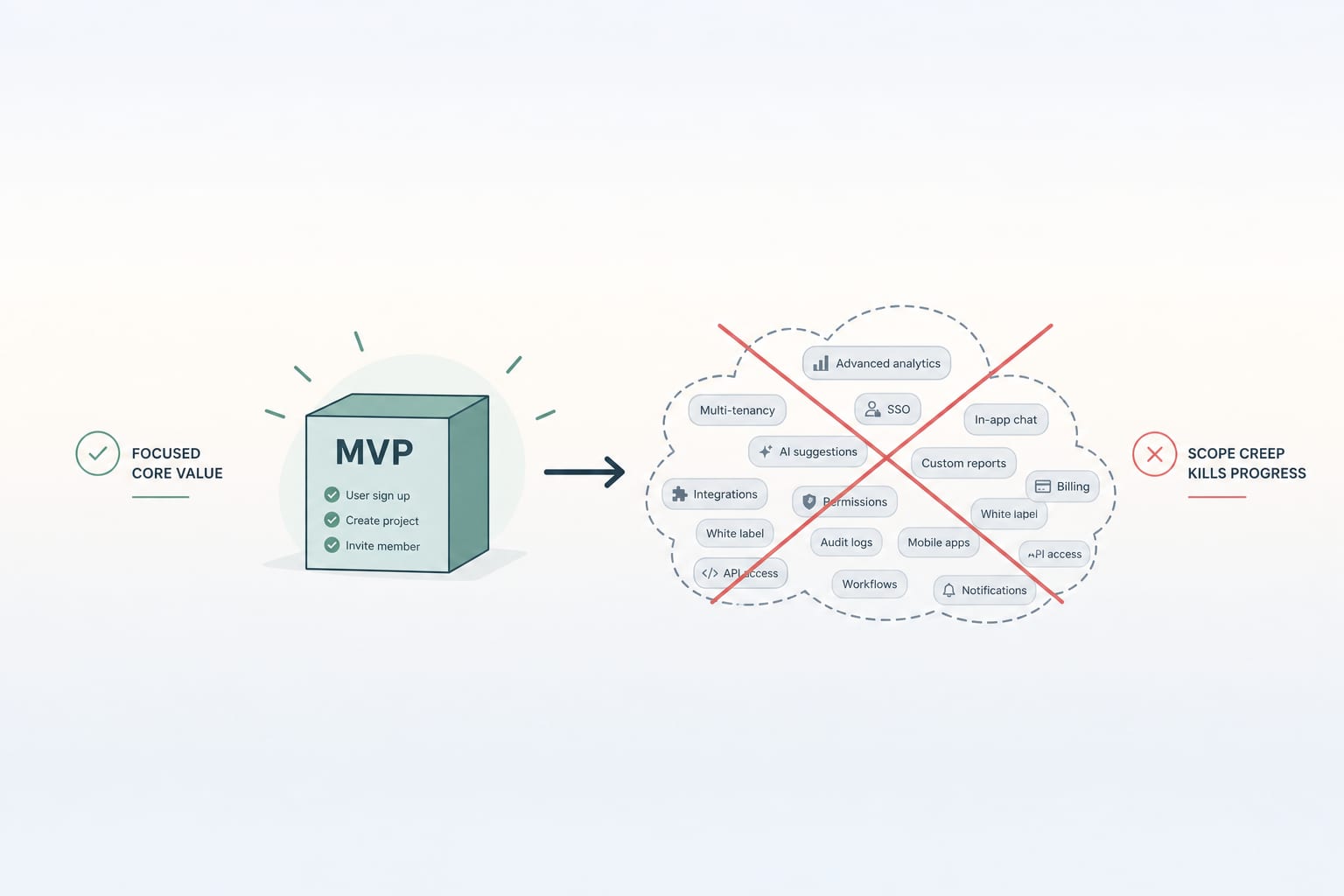
Ils ont livré un workflow de bout en bout, pas cinq workflows à moitié construits. Le MVP qui réussit résout un problème spécifique complètement pour un utilisateur spécifique. Inscription, action, résultat, valeur. Les MVP qui échouent ont typiquement un dashboard à moitié construit, un flux de facturation à moitié construit, une intégration à moitié construite, un panneau admin à moitié construit, et aucun ne fonctionne assez bien pour vraiment vendre.
Ils avaient un modèle de données qui fonctionnait avant un frontend qui fonctionnait. Le design de schéma qui ancre ce que sont les utilisateurs, comptes, plans et événements dans la base de données était stabilisé avant que l'UI ne soit construite. Les MVP qui reconstruisent depuis zéro reconstruisent généralement parce que le modèle de données initial ne pouvait pas représenter le modèle business qui a émergé des conversations clients.
Ils ont choisi des technologies ennuyeuses. Postgres, pas la dernière base vectorielle. Node ou Python ou Go, pas le nouveau langage. AWS ou Vercel, pas le fournisseur cloud lancé la semaine dernière. Les MVP qui réussissent dépensent leur budget d'innovation sur le produit, pas sur l'infrastructure.
Ils ont construit l'instrumentation dès la première semaine. Le MVP qui a livré avec logging, error tracking et analytics basique arrive à "on sait quelles fonctionnalités les clients utilisent" en deux mois. Celui qui ne l'a pas y arrive au mois neuf ou jamais.
Ils ont eu une transparence honnête sur les coûts. Les MVP qui survivent savent quelle sera leur facture AWS à 10 clients, 100 et 1 000. Ceux qui échouent sont surpris par une facture cloud de 4 000 $ au mois six et doivent mettre en pause le travail sur les fonctionnalités pendant un mois pour la corriger.
Ce ne sont pas des choix de framework. Ce sont des choix opérationnels. Le framework vient en aval.
Les cinq décisions d'ingénierie qui décident du résultat
Décision 1 : monolithe ou microservices
Le facteur le plus corrélé à l'échec d'un MVP que nous avons vu, c'est démarrer en microservices pour une équipe de 2 personnes qui construit un produit que personne n'a encore payé. L'overhead d'architecture est réel et il tue la vélocité.
Pour un MVP, la bonne réponse est presque toujours un monolithe. Une application, un repo, un déploiement. Le produit peut devenir un système distribué plus tard, après avoir su quelles sont les vraies frontières de service. Les frontières de service choisies trop tôt sont presque toujours fausses parce que le modèle business ne s'est pas stabilisé.
L'exception : un MVP qui est fondamentalement sur l'intégration de plusieurs systèmes externes (par exemple un produit middleware B2B) justifie souvent un service d'intégration séparé à côté de l'app principale dès le premier jour. Mais ce n'est pas du microservices ; c'est deux services. Deux services ne sont pas des microservices.
Nous avons vu des équipes livrer des MVP en monolithes et migrer vers des microservices à 1 000 clients, et la migration a été un projet de 6 mois. Nous avons vu des équipes livrer des MVP en microservices et arrêter avant d'atteindre 100 clients parce que l'équipe ne pouvait pas avancer assez vite. Le calcul favorise le monolithe pour les startups en stade MVP.
Décision 2 : quelle base de données, et comment modéliser les données
Postgres. Presque toujours Postgres. Les raisons ne sont pas excitantes : c'est mature, ça monte plus loin que ce dont vous aurez besoin pour le MVP, l'outillage est excellent, le vivier de recrutement est large, et les modes d'échec sont bien compris.
La décision intéressante n'est pas quelle base de données ; c'est comment modéliser le multi-tenancy. Trois patterns courants :
Schéma partagé, colonne tenant ID. Chaque table a une colonne tenant_id. Chaque requête filtre dessus. Le plus simple à opérer, le plus dur à rater (un WHERE tenant_id = ? manquant est une fuite de données). Utilisez Row-Level Security dans Postgres pour appliquer ça au niveau base, pas juste dans le code applicatif. Bonne réponse pour la plupart des MVP SaaS B2B.
Un schéma par tenant. Chaque tenant reçoit un schéma Postgres. Meilleure isolation, opérations plus complexes (migrations, sauvegardes, changements de schéma scalent linéairement avec le nombre de tenants). À utiliser quand vous avez un petit nombre de gros tenants (SaaS enterprise) plutôt qu'un grand nombre de petits.
Une base par tenant. Chaque tenant reçoit une base séparée (ou instance RDS). Isolation maximale, complexité opérationnelle maximale. À utiliser uniquement quand des exigences réglementaires ou contractuelles l'imposent (industries régulées, souveraineté des données par tenant). La plupart des MVP ne doivent pas démarrer ici.
Nous livrons typiquement les MVP sur le pattern schéma partagé avec Row-Level Security. Ça scale à des milliers de tenants, l'histoire opérationnelle est directe, et les modes d'échec sont documentés.
Décision 3 : où héberger
La décision d'hébergement affecte à la fois le coût initial et le coût de migration. Les deux comptent.
Vercel ou Netlify pour le frontend, AWS Lambda ou Render pour le backend, RDS ou Supabase pour la base. La stack "SaaS moderne". Rapide à démarrer, cher à l'échelle (le pricing fonction Vercel mord à partir d'un certain point), opinionated. Bon pour les MVP orientés contenu et les produits orientés frontend.
AWS de bout en bout (EC2 ou ECS ou Lambda, RDS, S3, CloudFront). Plus de flexibilité, plus de responsabilité opérationnelle. La plateforme qui scale le plus longtemps. Bon quand vous avez quelqu'un dans l'équipe à l'aise avec AWS ou que vous déployez aux côtés d'autres workloads AWS.
Fly.io ou Railway ou Render. Le tier "AWS pour gens qui ne veulent pas d'AWS". Plus facile qu'AWS brut, plus flexible que Vercel. Bon terrain d'entente pour les équipes sans capacité DevOps dédiée. Nous déployons ici pour les clients qui veulent la flexibilité d'auto-hébergement sans gérer l'infrastructure sous-jacente.
On-premise ou cloud souverain (OVH, Scaleway, Hetzner). Bon pour les clients européens avec des exigences RGPD strictes ou les clients français qui veulent spécifiquement une infrastructure hébergée en UE. Même pattern architectural que notre travail auto-hébergement n8n sur AWS ; les principes se transposent au cas d'usage SaaS.
La trajectoire de coût compte plus que le coût absolu au mois un. Nous avons vu des MVP sur Vercel qui fonctionnaient bien jusqu'au mois 10 quand la facture a touché 4 000 $/mois pour un produit qui générait 8 000 $/mois en revenus. Le coût de migration depuis Vercel à ce moment-là était plus élevé que le coût de migration aurait été s'ils avaient démarré sur Render.
Décision 4 : authentification, facturation, et build-vs-buy sur l'infrastructure
Les MVP qui livrent plus vite prennent des décisions agressives de build-vs-buy sur les fonctionnalités d'infrastructure. Ceux qui livrent moins vite essaient de tout construire eux-mêmes.
Authentification. Achetez. Auth0, Clerk, Supabase Auth, AWS Cognito, WorkOS pour le SSO enterprise. Construire l'auth depuis zéro pour un MVP, c'est un projet de 4 semaines qui gaspille du temps que vous n'avez pas. Le coût est réel (50 à 500 $/mois à l'échelle MVP) mais l'économie de temps est nettement plus grande.
Facturation. Achetez. Stripe est le choix évident, avec Stripe Billing qui gère les abonnements, la facturation et la taxe pour la majorité des SaaS B2B. Les exceptions : les produits avec une facturation à l'usage complexe où Lago ou Orb peuvent mieux rentrer, ou les produits qui ont besoin d'une intégration comptable extensive où un outil plus flexible que Stripe peut être nécessaire.
Emails transactionnels. Achetez. SendGrid, Postmark, Resend, AWS SES. L'infrastructure de délivrabilité n'est pas quelque chose à construire. Choisissez-en un, configurez SPF/DKIM/DMARC, passez à autre chose.
Recherche. Mixte. La recherche full-text de Postgres gère le MVP pour la plupart des produits. Algolia, Meilisearch ou Typesense sont justes quand vous avez sincèrement besoin de recherche classée sur des millions d'enregistrements et que l'approche Postgres n'est pas assez rapide.
Stockage de fichiers. Achetez. S3 ou Cloudflare R2. Pas d'exception.
Jobs en arrière-plan. Mixte. Un setup simple façon cron avec la base comme file (en utilisant SELECT FOR UPDATE SKIP LOCKED) gère le MVP. Passez à une vraie file (SQS, Sidekiq, BullMQ) quand vous en avez réellement besoin, généralement vers le moment où plusieurs workers tournent.
Le pattern : chaque fonctionnalité commodité est "achetez" jusqu'à ce que vous ayez une raison spécifique de construire. Les exceptions sont les fonctionnalités au cœur de la différenciation de votre produit, que vous devez construire parce qu'elles sont le produit.
Décision 5 : instrumentation dès le premier jour
Chaque MVP doit livrer avec trois choses instrumentées avant que le client #1 se connecte :
Application performance monitoring. Sentry, Honeycomb, Datadog, ou un outil similaire. Vous avez besoin de savoir quand des erreurs se produisent et quel utilisateur les a rencontrées. Pas cher à l'échelle MVP (25 à 100 $/mois). Inestimable quand un client se plaint et que vous pouvez lui montrer la trace d'erreur exacte.
Analytics produit. Mixpanel, PostHog, Amplitude. Tracking événementiel de ce que les utilisateurs font dans le produit. Vous ne ferez jamais les bonnes décisions produit si vous ne savez pas quelles fonctionnalités les utilisateurs utilisent vraiment. PostHog est open-source et auto-hébergeable, ce qui est le chemin que nous prenons typiquement pour les clients avec des exigences de souveraineté des données.
Dashboard de métriques business. Un dashboard simple (souvent Looker Studio, Metabase ou Retool) qui montre MRR, utilisateurs actifs, churn, et les 5 à 10 métriques qui comptent au business. Nous avons couvert l'architecture BI pour Shopify plus tôt ce mois-ci dans notre article Looker Studio + BigQuery ; les mêmes patterns s'appliquent au SaaS.
Les MVP qui livrent sans instrumentation la reconstruisent sous pression quand les investisseurs demandent les métriques. Construisez-la dès la première semaine.
⚠️
Le pattern d'échec MVP le plus courant que nous voyons, c'est "on instrumentera plus tard". Plus tard n'est jamais un bon moment parce qu'il y a toujours quelque chose d'urgent. Trois mois plus tard, l'équipe ne sait pas quelles fonctionnalités les clients utilisent, le churn arrive invisiblement, et la réunion de cofondateurs devient un débat sur quoi construire ensuite basé sur des opinions plutôt que des données. Instrumentez dès la première semaine. Le coût est trivial face au coût de voler à l'aveugle.
Le cadre de décision
Pour cadrer un build MVP SaaS, nous notons le projet sur quatre axes :
- Complexité du produit : workflow nouveau avec modèle de données flou (3), domaine complexe mais bien compris (1), produit simple type CRUD (0) ?
- Profondeur technique de l'équipe : ingénieurs seniors expérimentés (3), un ingénieur expérimenté plus des juniors (1), aucun ingénieur, fondateur première fois (0) ?
- Pression temporelle : deadline strict à 6 mois (3), 9 à 12 mois (1), flexible (0) ?
- Contraintes réglementaires ou de souveraineté des données : industrie régulée ou résidence UE stricte (3), quelques besoins de conformité (1), aucun (0) ?
Score 0 à 3 : un démarreur no-code ou low-code (Bubble, Retool, Glide) peut livrer plus vite qu'un MVP codé. Le produit est suffisamment simple, l'ingénierie de l'équipe n'est pas assez forte, et les contraintes sont assez légères pour que le code custom soit excessif.
Score 4 à 7 : stack MVP SaaS standard. Next.js ou Remix pour le frontend, Node ou Python pour le backend, Postgres, Vercel ou Render pour l'hébergement, Stripe pour la facturation, Auth0 ou Clerk pour l'auth. Livrer en 8 à 14 semaines. C'est la bande où la majorité de nos missions MVP SaaS atterrissent.
Score 8 à 12 : architecture custom, probablement hébergée AWS avec infrastructure-as-code, modèle de données réfléchi, et contrôles explicites de souveraineté des données. Le build tourne en 4 à 8 mois. La complexité justifie l'investissement d'ingénierie parce que le produit est sincèrement nouveau ou les exigences de conformité ne sont pas négociables.
C'est une heuristique, pas un verdict. Nous avons livré des MVP en 6 semaines pour des clients scorant 8 (quand l'équipe était très senior et le périmètre serré) et en 6 mois pour des clients scorant 4 (quand le produit a évolué pendant le build).
À quoi ressemble vraiment un build MVP
Pour un build MVP SaaS typique chez Sentinu, la mission se découpe en :
Semaines 1 à 2 : découverte et architecture. Cartographier les workflows utilisateur. Définir le modèle de données (c'est la semaine la plus importante du projet). Choisir les décisions de stack discutées ci-dessus. Mettre en place l'environnement de dev, le pipeline CI/CD et l'infrastructure initiale.
Semaines 3 à 6 : build cœur. Le workflow unique qui définit le produit. Inscription, action principale de l'utilisateur, résultat, chemin de retour. Authentification, facturation, modèle de données. Tout le reste est différé.
Semaines 6 à 9 : workflows secondaires. Panneau admin, paramètres, gestion de compte, deuxième et troisième workflows utilisateur. À ce point, le workflow principal est utilisé par des testeurs internes et l'équipe itère.
Semaines 9 à 12 : beta et lancement. Premiers clients payants. Bug fixes, travail de performance, les inévitables moments "on a découvert que le modèle de données a besoin d'un champ de plus". Déploiement production avec monitoring, alerting, rotation d'astreinte.
Semaines 12 et plus : opérer et itérer. Le MVP est en ligne. Le feedback client pilote la roadmap. Le travail de l'équipe passe de construire à écouter et itérer.
Un MVP focalisé à notre rythme livre en 10 à 14 semaines. La variabilité est dans le périmètre, pas dans la plateforme. Les MVP qui prennent plus longtemps ont typiquement essayé de livrer trop dans le périmètre initial plutôt que de différer à une v1.1.
Combien ça coûte
Fourchettes de coûts honnêtes pour les missions de développement de MVP SaaS :
| Forme du projet | Coût total d'ingénierie | Infra mensuelle |
|---|---|---|
| MVP SaaS standard, un workflow cœur, stack courante | 40 à 90 K$ | 100 à 400 $ |
| MVP avec une intégration externe (Shopify, HubSpot, Salesforce) | 60 à 120 K$ | 150 à 500 $ |
| MVP avec contraintes de conformité (RGPD, HIPAA léger) | 80 à 180 K$ | 300 à 800 $ |
| MVP enterprise avec SSO, audit logging, isolation multi-tenant | 120 à 300 K$ | 500 à 2 000 $ |
Le coût d'infrastructure est la part que les fondateurs sous-estiment constamment. Un MVP hébergé Vercel à 40 $/mois en semaine un est à 400 $/mois à 50 clients et 2 000 $/mois à 500. Le coût de migration depuis une plateforme d'hébergement que vous avez choisie pour le confort de dev peut être de 20 à 60 K$ selon l'architecture. Le choix de plateforme en semaine 1 a des conséquences au mois 24.
Quand sauter le MVP et valider autrement
Le contre-exemple honnête. Toutes les idées de produit n'ont pas besoin d'un MVP codé.
Validez la demande d'abord. Si vous n'avez pas eu 20 conversations avec des clients potentiels qui ont dit qu'ils paieraient pour le produit, vous n'avez pas besoin d'un MVP. Vous avez besoin de plus de conversations. Les MVP qui échouent le plus systématiquement sont ceux construits avant que le product-market fit n'ait même été hypothétisé.
MVP concierge. Délivrez la valeur manuellement aux 5 à 10 premiers clients avant de l'automatiser. Si vous ne pouvez pas délivrer la valeur manuellement, le produit ne résout pas le bon problème. Si vous le pouvez, vous avez la preuve que l'automatisation vaut le coup d'être construite.
Test de landing page. Une landing avec liste d'attente, une proposition de valeur claire, et 200 inscriptions en 30 jours a plus de valeur qu'un MVP construit en isolation. Nous avons conseillé à des fondateurs de retarder le build MVP de 8 semaines pendant qu'ils validaient la demande, et le MVP résultant a livré plus vite et a survécu plus longtemps.
Nous refusons sincèrement des missions MVP quand nous pensons que le fondateur doit valider d'abord plutôt que construire. La conversion de "veut un MVP" vers "doit construire un MVP" est autour de 70 pour cent des demandes que nous recevons.
Ce que nous livrons chez Sentinu
Des missions récentes de MVP SaaS illustrent l'éventail :
- Un outil de conformité B2B français, Next.js + Node.js + Postgres sur Scaleway (la résidence UE n'était pas négociable). Build de 14 semaines. En ligne avec 6 clients enterprise au premier mois.
- Un MVP fintech britannique, Remix + Postgres sur Fly.io, avec intégration extensive Stripe Connect pour la facturation marketplace. Build de 16 semaines, 3 mois de travail de validation pré-MVP.
- Un SaaS B2B canadien pour l'industrie du bâtiment, Next.js + Python (Django) + Postgres sur AWS, avec application mobile compagnon offline-first. Build de 22 semaines, 8 clients depuis une liste d'attente de 50 établie avant le début du développement.
Le pattern : les MVP qui ont marché avaient des fondateurs qui savaient exactement quel workflow ils construisaient, ont validé la demande avant développement, et ont traité l'ingénierie comme la décision la plus stratégique de la jeune entreprise. Ceux que nous avons refusés avaient typiquement des fondateurs excités par une idée de produit mais qui n'avaient pas encore gagné le droit de le construire.
FAQ
Dois-je utiliser TypeScript ou JavaScript pur pour le MVP ?
TypeScript, pour tout projet attendu pour vivre plus de 6 mois. Le coût de démarrage est petit (quelques heures de setup en plus) et le gain de productivité issu des bugs attrapés et de la confiance au refactoring compose lourdement. Les exceptions sont les très petits MVP (sous 5 000 lignes de code) où l'overhead de vérification de types n'est pas justifié, mais la plupart des MVP grandissent au-delà.
Et le code généré par IA ou la programmation en binôme avec IA ?
Utilisez-le. Les outils IA (Cursor, Windsurf, Claude Code, GitHub Copilot) accélèrent sincèrement le développement de MVP pour l'ingénieur expérimenté qui sait quand accepter la sortie et quand la surcharger. Le piège, c'est les ingénieurs juniors qui livrent du code généré par IA qu'ils ne comprennent pas, ce qui crée une dette de maintenabilité. Comme multiplicateur de productivité pour ingénieurs seniors, les outils IA sont maintenant standards. Comme substitut au jugement d'ingénierie senior, ils ne le sont pas.
Combien doit coûter le MVP comparé à ma levée ?
Règle empirique : le coût de développement du MVP ne doit pas dépasser 30 à 40 pour cent de votre runway seed, laissant du budget pour les 6 à 12 mois d'itération post-MVP qui déterminent le product-market fit. Un MVP qui consomme 70 pour cent du financement seed laisse l'entreprise incapable d'itérer après le lancement, qui est exactement quand l'itération compte le plus.
Construire avec un freelance ou une agence ?
Pour un MVP, le facteur décisif est la profondeur d'ingénierie et la continuité. Un freelance senior avec un track record MVP documenté peut livrer un MVP comparable à une agence, souvent à coût moindre. Le risque, c'est la période de 12 mois post-MVP quand des bugs doivent être corrigés et des itérations doivent être livrées. Si le freelance devient indisponible, le MVP est souvent reconstruit. Les agences offrent succession et continuité d'équipe à coût plus élevé. La bonne réponse dépend de votre tolérance à ce risque.
Et si mon MVP doit être en ligne dans 6 semaines ?
La forme réaliste d'un MVP en 6 semaines : un workflow, un type d'utilisateur, pas de panneau admin, pas de multi-tenancy au-delà des bases, pas d'analytics au-delà du plus basique. La plupart des produits ne peuvent pas honnêtement rentrer dans 6 semaines. Ceux qui le peuvent sont des produits où le workflow est sincèrement simple (un scheduler de contenu, une app form-vers-base basique, une intégration Slack). Les fondateurs qui pensent que leur produit rentre dans 6 semaines n'ont généralement pas encore vu la complexité de modèle de données qui émerge des vrais besoins clients.
Comment ça se connecte à votre travail Shopify ?
Beaucoup de nos MVP SaaS sont des outils qui s'intègrent à Shopify (outils d'inventaire, apps post-achat, portails B2B). Le travail d'intégration Shopify couvert dans nos articles intégration Shopify NetSuite et App custom vs publique est le même pattern d'ingénierie : intégration API, gestion de webhooks, design du modèle de données. Les principes se transfèrent proprement.
Le MVP doit-il être open source ou propriétaire ?
Presque toujours propriétaire pour le MVP. L'open source est une décision stratégique (construction de communauté, adoption développeur, modèle business freemium) qui doit être prise délibérément, pas par défaut. La plupart des MVP SaaS bénéficient d'être propriétaires pendant que le product-market fit est en train d'être trouvé ; l'open source devient une option plus tard une fois que la proposition de valeur est plus claire.
Pour aller plus loin
Si vous cadrez un build MVP SaaS et que le cadre ci-dessus a réduit l'espace de décision mais que vous voulez un partenaire pour livrer le build, c'est ce que couvre notre pratique développement SaaS et application web. Nous cadrons, architecturons et livrons des MVP là où le travail de validation a été fait et où les décisions d'ingénierie sont le prochain goulot. Si le build implique aussi de l'intégration avec Shopify ou d'autres plateformes commerce, notre pratique intégration API et système est le complément. Et si la conversation est encore en territoire "validez d'abord", nous le dirons et recommanderons le travail de validation avant l'ingénierie.
Articles connexes
Tous les articles
Custom SoftwareJun 24, 2026
CRM sur mesure vs CRM du commerce en 2026 : quand construire le sien gagne réellement
La plupart des équipes devraient acheter un CRM. Certaines ne devraient pas. Voici le cadre de décision que nous utilisons avec les clients, les calculs de coût à l'échelle, et les formes opérationnelles spécifiques où un build sur mesure surpasse HubSpot, Salesforce et les alternatives moins coûteuses.
14 min de lecture

Growth StrategyMay 21, 2026
Le règlement IA de l'UE pour l'ecommerce après le report de mai 2026 : ce qui reste obligatoire, ce qui est repoussé, et quoi faire avant décembre
Le 7 mai 2026, les législateurs de l'UE ont accepté de reporter des parties du règlement IA. Mais les règles de transparence sur les chatbots n'ont pas été beaucoup reportées. Voici ce qu'une boutique ecommerce doit réellement faire, et pour quand.
13 min de lecture
Custom SoftwareMay 26, 2026
Choisir l'authentification pour un nouveau SaaS en 2026 : Clerk, Auth.js, Supabase Auth, Better Auth, et quand auto-héberger
L'authentification est la partie la moins excitante d'un build SaaS jusqu'à ce qu'elle casse ou que la facture arrive. Voici comment nous choisissons entre Clerk, Auth.js, Supabase Auth, Better Auth et un build sur mesure pour les projets clients en 2026.
13 min de lecture