Le dashboard analytics Shopify qui va au-delà de GA4 : Looker Studio + BigQuery
Le guide d'ingénieur pour construire une vraie stack analytics Shopify sur Looker Studio et BigQuery. Architecture KPI, pipelines ETL, quand utiliser un template ou construire, et le reporting qualité CFO que Shopify Analytics ne livrera jamais.
15 min de lecture

L'analytics intégré à Shopify convient aux métriques opérationnelles qu'un responsable de boutique surveille au jour le jour. Ce n'est pas ce que votre CFO veut. Ce n'est pas ce que votre directeur marketing a besoin pour évaluer les dépenses pub entre canaux. Ce n'est pas ce que votre responsable opérations a besoin pour prévoir l'inventaire du trimestre prochain. Les marchands qui dépassent Shopify Analytics n'ont pas besoin d'un "meilleur dashboard" ; ils ont besoin d'une vraie stack BI, et la question, c'est quoi construire, combien ça coûte, et où passe la ligne entre "acheter un template" et "ingénier la réponse".
Cet article est l'architecture BI que nous déployons chez Sentinu pour les clients Shopify qui ont atteint les limites du reporting natif et ont décidé d'investir dans une vraie infrastructure analytique. Il s'appuie directement sur notre article tracking côté serveur (qui vous donnait des événements propres et complets) et répond à la question suivante : maintenant que la donnée est fiable, où vit-elle et comment devient-elle des décisions ?
Ce que Shopify Analytics ne sait pas faire
Trois catégories de questions auxquelles les dashboards natifs de Shopify ne répondent pas bien, et auxquelles chaque boutique en croissance a besoin de réponses :
Profitabilité au niveau SKU après retours, remboursements, dépenses pub et frais. Shopify vous montre le chiffre d'affaires. Il ne vous montre pas le profit net par SKU après soustraction du coût d'acquisition client mélangé, des vrais frais de transaction, des taux de retour par SKU et du coût de l'inventaire qui dort dans l'entrepôt. Les décisions qualité CFO ont besoin de ce chiffre ; Shopify Analytics ne vous le donne jamais.
Attribution multicanale. Un client voit votre pub Meta mardi, ouvre un email mercredi, clique sur une pub Google search jeudi, et convertit vendredi. Shopify Analytics vous montre vendredi. GA4 avec modélisation d'attribution s'approche mais peine encore avec les canaux offline (wholesale, en personne, commercial B2B). La vraie BI joint les commandes Shopify aux données de dépenses pub, aux données d'engagement email, et à tout autre canal qui a touché le parcours client.
Analyse de cohortes sur le cycle de vie client. LTV client par cohorte d'acquisition. Taux de rachat par premier produit acheté. Churn d'abonnement par tier. Ces questions ont besoin de données qui croisent les périodes et joignent les fiches clients aux commandes, produits et événements marketing. Les rapports de cohortes natifs Shopify sont basiques ; la vraie analyse de cohortes vit dans un data warehouse.
Reporting multi-boutiques ou omnicanal. Une marque qui fait tourner deux boutiques Shopify plus une opération wholesale plus une présence retail a besoin d'un reporting consolidé sur les quatre. Les rapports Shopify sont par boutique. Vous consolidez par export et jointure ailleurs, ou en vivant dans un outil BI qui tire des quatre sources.
L'architecture
La stack que nous déployons pour de l'analytics Shopify sérieux en 2026 a quatre couches :
Les décisions d'architecture à souligner :
BigQuery comme entrepôt, pas comme une "destination de connecteur Shopify". Le data warehouse est la couche persistante qui contient tout : Shopify, GA4 (via l'export BigQuery), Google Ads, Meta Ads, engagement de la plateforme email, NetSuite ou votre ERP si applicable. Looker Studio interroge l'entrepôt. Tout le reste, c'est de la plomberie.
Trois schémas, pas une table géante. La zone d'atterrissage brute préserve la donnée source telle quelle, avec timestamps. Le staging nettoie, déduplique, applique la logique métier (ce qui compte comme une "commande terminée"). Les marts sont les tables prêtes pour le métier que Looker Studio lit. Cette séparation permet de retraiter les couches staging et marts quand les règles métier changent sans retirer de la source.
Looker Studio comme couche de présentation, pas comme l'entrepôt. Les connecteurs natifs de Looker Studio vers Shopify ou GA4 conviennent aux dashboards les plus simples. Pour de la vraie analytics, le connecteur pointe vers BigQuery, et BigQuery fait le gros du travail. Cette séparation compte parce que les extracts de données de Looker Studio sont limités et lents sur les gros datasets ; BigQuery gère des milliards de lignes confortablement.
Quand templater, quand construire
La question la plus fréquente des marchands à ce stade : "Je peux pas juste utiliser un des templates Looker Studio de Supermetrics ou Coupler ?"
Réponse honnête : oui, pour les 60 premiers pour cent de ce dont vous avez besoin. Les templates pré-construits de Supermetrics, Coupler, Two Minute Reports, Power My Analytics, Funnel et similaires couvrent les KPI ecommerce standards (tendances de chiffre d'affaires, top produits, funnel de conversion, segmentation client basique). Ils sont templatés précisément parce que ces patterns se généralisent. Si votre question de reporting est "montre-moi les ventes par produit dans le temps", un template y répond.
Les templates se cassent au même point où Shopify Analytics se casse : quand la question demande de joindre la donnée entre sources, de calculer des métriques custom qui impliquent de la logique métier spécifique, ou de faire remonter des KPI qui dépendent de données que le connecteur n'expose pas.
La ligne que nous traçons chez Sentinu :
Utilisez un template quand : la question peut être répondue par la donnée Shopify seule. Le connecteur couvre la métrique. La présentation est la valeur. Vous voulez un dashboard fonctionnel en un jour, pas une semaine.
Construisez custom quand : la question demande de joindre Shopify avec des dépenses pub, des données ERP, ou du tracking d'événements custom. La métrique demande une logique métier spécifique (formules de marge custom, fenêtres d'attribution custom, définitions de cohorte custom). L'audience est exécutive et a besoin d'une présentation calibrée pour des décisions spécifiques.
Une vraie mission BI est généralement les deux. Templates pour les dashboards opérationnels, custom pour les stratégiques.
La couche ETL : où l'ingénierie se passe vraiment
Le data warehouse est la couche qui détermine si votre analytics monte à l'échelle. Le connecteur Shopify que vous choisissez pour le remplir compte plus que le dashboard que vous mettez dessus.
Fivetran. Le défaut cher. 150 à 1 500 $+ par mois pour Shopify seul selon le nombre de lignes actives mensuelles. Éprouvé. Forte gestion du schéma. Gère les chargements incrémentaux, la dérive de schéma et les backfills historiques proprement. À utiliser quand la fiabilité compte plus que le coût, ce qui est la plupart des scénarios enterprise.
Stitch. Alternative moins chère (100 à 500 $/mois). Gestion de schéma moins mature. Marche pour les boutiques mid-market avec un volume de données raisonnable. L'histoire du backfill historique est plus rugueuse que Fivetran.
Airbyte (auto-hébergé ou cloud). Open-source, auto-hébergeable. 0 $ si vous le faites tourner vous-même, 100 à 1 000 $/mois pour Airbyte Cloud. Même pattern architectural que notre setup n8n auto-hébergé. Bonne réponse pour les équipes qui veulent une résidence des données UE et ont la capacité DevOps.
Python custom sur AWS Lambda. Ce que nous construisons pour les clients qui scorent haut en souveraineté de données (une industrie régulée française par exemple) ou ont des exigences de transformation inhabituelles. Une Lambda qui tire de l'Admin API Shopify sur un calendrier, transforme et écrit dans BigQuery. Coûte 20 à 200 $/mois en AWS. Coûte 30 à 60 K$ à construire initialement. Bonne réponse pour le petit nombre de clients où le sur étagère ne rentre pas.
Le pattern à travers tout ça : le bon outil dépend des mêmes axes qui ont décidé du choix d'intégration Shopify NetSuite la semaine dernière. Volume de données, besoin de personnalisation, capacité d'ingénierie interne. Le cadre se transfère.
Ce qui va dans le schéma marts
La couche marts, c'est où vit la logique métier. Exemples de tables que nous construisons pour les projets analytics Shopify typiques :
fact_orders. Une ligne par commande. Inclut order ID, customer ID, devise, chiffre d'affaires brut, montant de remise, taxe, livraison, montant remboursé, chiffre d'affaires net, pays de commande, canal, statut de fulfillment et timestamps. Joint aux clients et produits pour l'analyse en aval.
fact_line_items. Une ligne par ligne de commande. Inclut SKU, product ID, variant ID, quantité, prix unitaire, coût des marchandises vendues (joint depuis la donnée de coût produit), et quantités ajustées des remboursements. Le grain auquel l'analyse de marge se fait.
dim_customers. Une ligne par client avec attributs dérivés : date de première commande, date de dernière commande, total commandes, total chiffre d'affaires, total remises reçues, LTV client, segments RFM (recency, frequency, monetary), et canal d'acquisition. Recalculée chaque nuit.
dim_products. Une ligne par variante de produit avec pricing actuel et historique, coût, niveaux d'inventaire, taux de retour, marge moyenne, et attributs de catégorie.
fact_marketing_spend. Dépenses marketing quotidiennes par canal (Google Ads, Meta, email, affiliation). Jointes au chiffre d'affaires des commandes pour les calculs de return-on-ad-spend. C'est la table qui vous permet de répondre à "quel était le ROAS par campagne au dernier trimestre".
fact_customer_cohorts. Table de cohortes qui regroupe les clients par mois d'acquisition, avec chiffre d'affaires et rétention mesurés à 1, 3, 6, 12 et 24 mois post-acquisition. C'est la table qui répond à "est-ce que nos cohortes plus récentes convertissent et retiennent mieux ou moins bien que celles de l'an dernier".
Ce sont des points de départ. Des clients spécifiques ont besoin de tables additionnelles pour les abonnements, comptes B2B, commandes wholesale ou métriques opérationnelles. Le pattern est le même : une table de faits par événement métier, une table de dimension par entité, des marts directement interrogeables par Looker Studio.
💡
La partie la plus dure de construire une stack BI Shopify, ce n'est pas les dashboards. C'est le design des tables de dimension et de faits. Ratez ça et chaque dashboard construit dessus a la mauvaise réponse. Réussissez ça et ajouter de nouveaux dashboards devient un exercice de drag-and-drop dans Looker Studio. Investissez le temps d'ingénierie à cette couche.
Les dashboards qui sont vraiment utilisés
À travers nos clients BI, les dashboards qui sont ouverts quotidiennement contre ceux qui sont construits et oubliés suivent un pattern. Ceux qui réussissent partagent trois propriétés :
Ils répondent à une question spécifique. Les dashboards "KPI quotidien exec" qui essaient de montrer 40 métriques sur une page ne sont pas utilisés. Les dashboards "chiffre d'affaires quotidien contre cible avec attribution par canal" le sont. La discipline, c'est de nommer la question à laquelle le dashboard répond avant de le construire.
Ils font remonter de l'action, pas juste de la donnée. Un dashboard qui montre le CAC d'hier est informationnel. Un dashboard qui montre le CAC d'hier aux côtés du seuil auquel vous devriez mettre la campagne en pause est actionnable. Les bons dashboards incluent des seuils, des cibles et des états de santé codés en couleur.
Ils sont liés à une réunion ou une décision. Le dashboard de revue marketing du lundi. Le dashboard CFO de clôture mensuelle. Le dashboard de réapprovisionnement inventaire hebdomadaire. Les dashboards sans décision attachée dérivent vers le non-usage en quelques semaines.
Les dashboards que nous construisons typiquement pour un client Shopify Plus :
| Dashboard | Audience | Fréquence | Tables clés |
|---|---|---|---|
| KPI exec quotidiens | CEO, direction | Quotidien | fact_orders, fact_marketing_spend |
| Performance marketing | CMO, équipe marketing | Quotidien/hebdo | fact_marketing_spend, fact_orders, dim_customers |
| Clôture finance CFO | CFO, finance | Mensuel | fact_orders, fact_line_items, dim_products |
| Profitabilité produit | Merchandising | Hebdo | fact_line_items, dim_products |
| Cohortes clients et LTV | Stratégie, finance | Trimestriel | dim_customers, fact_customer_cohorts |
| Inventaire et réapprovisionnement | Opérations | Quotidien | dim_products, fact_orders |
| Santé des abonnements (si applicable) | Produit, finance | Hebdo | Tables d'abonnement custom |
Chaque rapport est un Looker Studio séparé. Chacun tire depuis les mêmes marts BigQuery. Chacun est cadré sur une audience et une décision.
Combien ça coûte
Coût honnête d'infrastructure pour une boutique Shopify Plus à 50K commandes par mois, 100K clients, stack BI standard :
| Composant | Coût mensuel |
|---|---|
| Fivetran (connecteur Shopify, ~50K MAR) | ~300 $ |
| Stockage BigQuery (10 Go compressés) | ~2 $ |
| Compute de requête BigQuery (~500 Go scannés/mois) | ~5 $ |
| Looker Studio | 0 $ |
| Optionnel : connecteurs Google Ads / Meta Ads | ~200 $ |
| Total mensuel | ~510 $ |
Coût de setup d'ingénierie pour une implémentation propre : 25 à 60 K$ selon le nombre de tables marts, la complexité de la logique métier (formules de marge custom, métriques d'abonnement) et le nombre de dashboards.
Maintenance continue : typiquement 1 à 2 jours par mois de travail d'analytics engineering pour mettre à jour la logique des marts, ajouter de nouvelles dimensions à mesure que le business évolue, et tuner les requêtes. Les boutiques plus petites peuvent tourner sans attention pendant des mois ; les plus grosses avec des lancements produits actifs et des changements marketing ont besoin de plus d'attention.
Comparer aux alternatives : un outil BI managé comme Triple Whale commence à 300 $/mois et monte vite avec la taille de la boutique ; Polar Analytics est entre 300 et 1 500 $/mois. Ces outils sont justes quand l'équipe n'a pas de capacité d'ingénierie et que les besoins analytiques mappent sur leurs rapports pré-construits. Ils sont faux quand l'équipe a la capacité d'ingénierie et veut construire les métriques spécifiques à son business.
Quand sauter complètement la couche BigQuery
Le contre-exemple honnête. Toutes les boutiques Shopify n'ont pas besoin de BigQuery.
Boutiques sous 5 M$ de GMV annuel avec des besoins analytiques simples. Le volume de données ne justifie pas la complexité de l'entrepôt. Un connecteur Looker Studio direct vers Shopify, plus le connecteur natif GA4, plus un template Supermetrics pour les dépenses pub, couvre 80 pour cent du besoin pour un dixième du coût.
Équipes sans capacité d'ingénierie. Un setup BigQuery a besoin de quelqu'un qui sait écrire du SQL, déboguer les échecs de pipeline de données, et mettre à jour les marts à mesure que la logique métier change. Si l'équipe est purement marketing-et-ops, un outil BI managé (Triple Whale, Polar Analytics, Glew) est la bonne réponse même s'il coûte plus.
Cas d'usage très tactiques. Une équipe qui veut "performance de campagne cette semaine" y arrive avec un template. Une équipe qui veut "LTV par cohorte d'acquisition avec attribution multicanale" a besoin de l'entrepôt.
La question décisive n'est pas la taille de la boutique mais la sophistication analytique. Nous avons vu des marques à 20 M$ tourner parfaitement bien sur des connecteurs Looker Studio directs et des marques à 3 M$ ayant sincèrement besoin d'un entrepôt parce que leur business est lourd en abonnements avec de l'analyse de cohortes complexe. Le GMV annuel de la boutique est un faible proxy de la complexité analytique.
FAQ
Pourquoi BigQuery et pas Snowflake ou Redshift ?
Pour une stack analytics Shopify hébergée aux côtés de GA4 (qui exporte nativement vers BigQuery), BigQuery est le chemin de moindre résistance. Snowflake est plus flexible sur plusieurs cloud providers et a de meilleures fonctionnalités de gouvernance pour les grandes entreprises. Redshift est le choix naturel pour les stacks AWS-lourdes. Pour une boutique Shopify mid-market avec GA4 comme source de données principale, BigQuery gagne sur l'intégration et le coût.
Et Power BI pour Shopify ?
Power BI est le bon choix pour les organisations standardisées sur Microsoft (Office 365, Azure, Dynamics). Il se connecte à Shopify via des connecteurs partenaires (histoire similaire à Looker Studio) et à BigQuery, Snowflake ou Redshift. Le choix d'outil de dashboard (Looker Studio vs Power BI vs Tableau) est secondaire face à l'architecture de l'entrepôt. Choisissez l'outil de dashboard que votre audience utilise déjà.
Combien de temps prend une implémentation BI ?
Du kickoff aux premiers dashboards utilisables : 6 à 10 semaines pour une implémentation focalisée (un connecteur, un entrepôt, quatre dashboards). Les projets plus grands avec données multi-sources, logique métier custom et 10+ dashboards tournent 3 à 5 mois. La variable, c'est la complexité du design des marts, pas la technologie.
Puis-je le faire moi-même sans agence ?
Oui, si vous avez un data engineer ou analytics engineer dans l'équipe. La stack Fivetran-BigQuery-Looker Studio est bien documentée et le setup des connecteurs est essentiellement du point-and-click. La partie dure, c'est le design des marts, qui demande à la fois de la compétence data engineering et du contexte métier pour être bien fait. Les équipes qui ont sauté cette étape se retrouvent avec des dashboards qui montrent le mauvais chiffre aux dirigeants.
Comment ça marche avec Shopify B2B ?
Les commandes B2B passent par la même Admin API Shopify et le même connecteur Fivetran. Elles apparaissent comme des commandes avec une association Company plutôt qu'un client direct. Le schéma des marts a besoin d'une table dim_companies jointe à dim_customers, et de tables de faits B2B-spécifiques pour des choses comme l'usage de listes de prix et la facturation Net. Même architecture, dimensions additionnelles. Nous avons couvert la couche B2B dans notre article Shopify Plus B2B.
Et les dashboards temps réel ?
BigQuery n'est pas conçu pour de la latence sub-seconde. Si votre dashboard a besoin de se mettre à jour quelques secondes après une commande, vous regardez des architectures streaming (Pub/Sub, Kinesis, ClickHouse) qui sont plus chères et complexes. Pour 99 pour cent de l'analytics business, un rafraîchissement horaire ou quotidien suffit. Nous utilisons le temps réel uniquement pour des dashboards opérationnels spécifiques (monitoring de commandes en direct pendant un push de vente) et acceptons le coût additionnel là.
Comment le RGPD affecte-t-il la stack BI ?
BigQuery propose des régions UE. Fivetran propose la résidence des données UE sur les tiers appropriés. Looker Studio est un produit Google soumis aux engagements standards de résidence des données Google. Pour les clients français sous RGPD, nous configurons la stack avec BigQuery en région UE, Fivetran en résidence UE, et des Data Processing Agreements documentés. Même pattern architectural que notre travail sur le tracking côté serveur et n8n auto-hébergé ; les principes se transfèrent à travers la stack de données.
Pour aller plus loin
Si vous cadrez un build BI Shopify et que l'architecture ci-dessus résonne avec ce dont votre équipe a besoin, c'est ce que couvre notre pratique analyse de données et BI. Nous designons le schéma des marts, construisons l'ETL et livrons les dashboards que votre équipe va réellement utiliser. Si le projet implique aussi de nettoyer la couche de tracking amont (pour que la donnée dans BigQuery soit fiable au départ), notre article tracking côté serveur est le prérequis. Si vous n'êtes pas encore au volume qui justifie BigQuery et que vous voulez un chemin templaté, la même équipe peut vous cadrer sur un setup Looker Studio direct et gagner la mission sur le build d'entrepôt quand vous serez prêt.
Articles connexes
Tous les articlesTechnical SEOFeb 17, 2026
Tracking côté serveur pour Shopify : une configuration GTM et GA4 qui survit aux ad blockers et au RGPD
Le guide d'ingénieur pour le tracking côté serveur sur Shopify en 2026. Pourquoi les ad blockers mangent vos données, comment configurer GTM côté serveur sur AWS, le réglage GA4, les contrôles RGPD et le coût réel.
14 min de lecture
Shopify DevelopmentJun 17, 2026
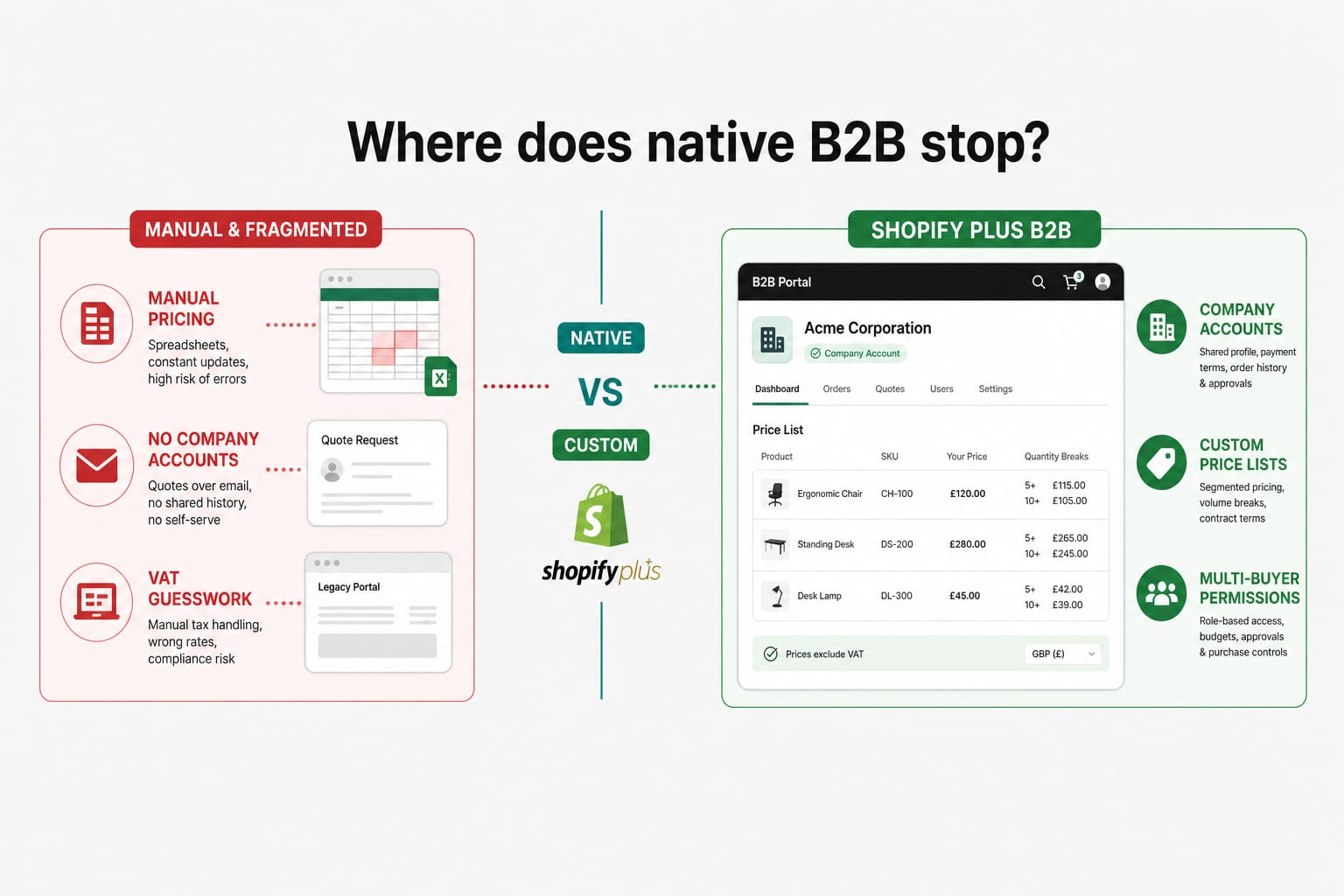
Construire un portail B2B wholesale sur Shopify Plus en 2026 : fonctionnalités natives, limites, et là où le développement custom commence
Le B2B Shopify a grandi. Pour la plupart des opérations wholesale, les fonctionnalités Plus natives couvrent les bases. Pour la logique d'exemption TVA, les prix synchronisés depuis l'ERP, les comptes multi-acheteurs et les conditions de paiement à crédit, la ligne entre natif et custom est là où la plupart des boutiques se coincent. Voici comment la tracer.
13 min de lecture
Shopify DevelopmentJun 10, 2026
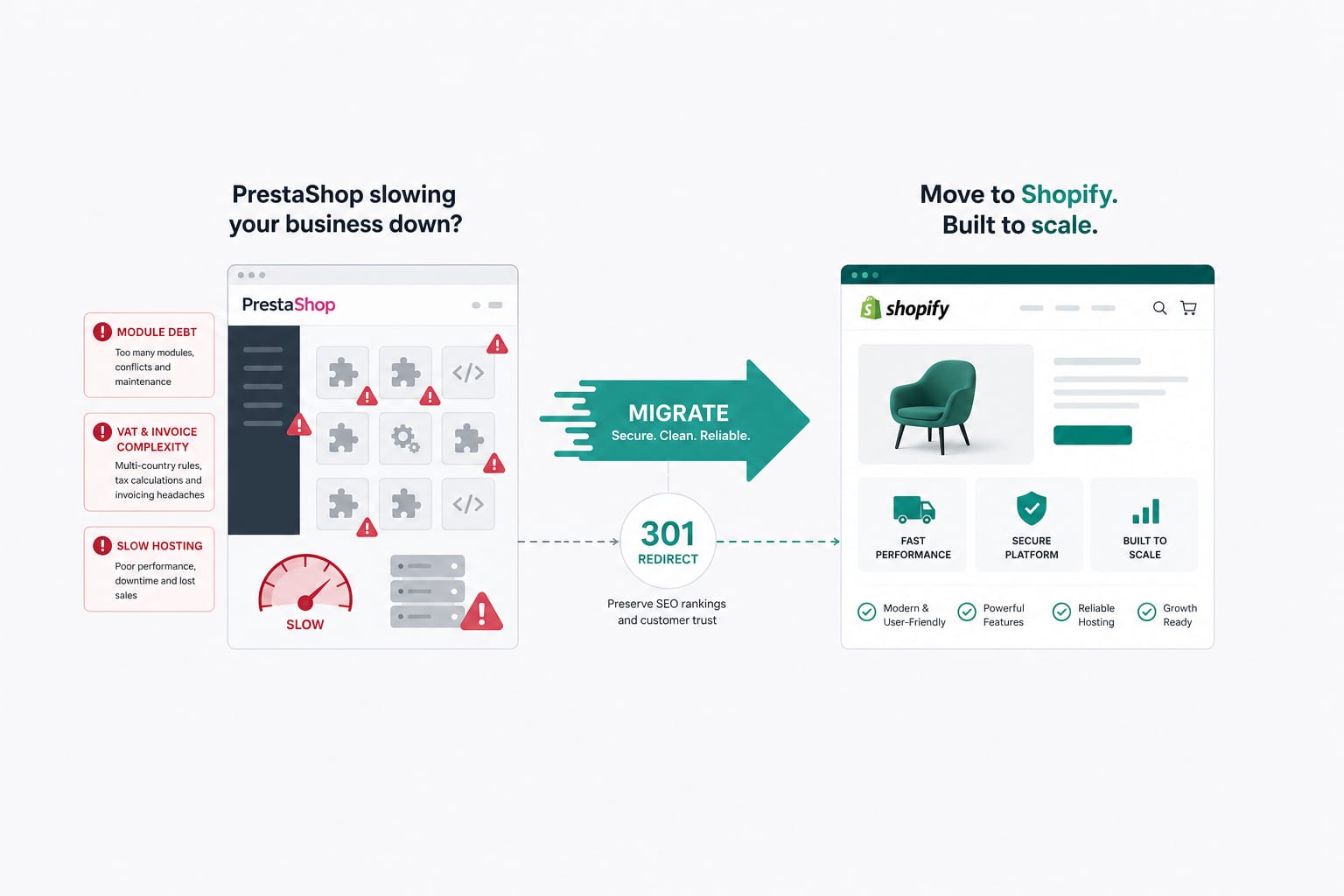
Migration PrestaShop vers Shopify en 2026 : le playbook pour le marché français
Les migrations PrestaShop ne sont pas des migrations WooCommerce avec une autre étiquette. Le modèle de données, l'écosystème de modules, la logique TVA et facturation, et les attentes légales françaises diffèrent. Voici le playbook que nous appliquons pour les marchands français et UE qui quittent PrestaShop pour Shopify.
20 min de lecture